Applying sentiment analysis on IATF resolutions
Steps in performing sentiment analysis using R
 Image credit: CoMo Philippines
Image credit: CoMo Philippines
Sentiment analysis or opinion mining as it’s sometimes called is commonly used to assess affective states and subjective information such as opinion and attitudes of subjects of interest using language 1,2. The most common use case of sentiment analysis is on analysing product or service reviews that are made available on the internet but it is increasingly being used in research that aims to quantify public sentiment or opinion. In the advent of Web 2.0 and wide use of various social media platforms alongside much affordable access to increased computing power for most people, the use of sentiment analysis has increased and expanded to various fields such as stock and financial markets, elections, extreme events and disaster, medicine, and policy analysis1.
Using the text data on IATF resolutions available from the covidphtext package we developed, we explore the use of sentiment analysis as one of several natural language processing (NLP), text analysis and computational linguistics techniques we plan to use for assessing Philippine government policy with regard to the response to the COVID-19 pandemic. The following workflow illustrates the process we use:
Figure 1: Sentiment analysis workflow
Step 1: Text data: covidphtext
As described in an earlier post, the covidphtext contains IATF resolutions text data structured for the purpose of text analysis. What we need to do now is to combine all resolutions into a single dataset. There is a convenience function in covidphtext that helps with this called combine_iatf and is used as follows:
allText <- covidphtext::combine_iatf(res = c(1:15, 17:46))You will notice that we left out IATF Resolution No. 16.. This resolution is the only resolution that has been written in Filipino (see below).
## # A tibble: 87 x 7
## linenumber text source type id section date
## <int> <chr> <chr> <chr> <dbl> <chr> <date>
## 1 1 Inter-Agency Task Force f… IATF resolu… 16 heading 2020-03-30
## 2 2 Additional Guidelines for… IATF resolu… 16 heading 2020-03-30
## 3 3 March 30, 2020 IATF resolu… 16 heading 2020-03-30
## 4 4 Resolution No. 16 IATF resolu… 16 heading 2020-03-30
## 5 5 A. Ayon sa direktiba ng D… IATF resolu… 16 operat… 2020-03-30
## 6 6 Autonomous Region in Musl… IATF resolu… 16 operat… 2020-03-30
## 7 7 mga pasilidad na maaring … IATF resolu… 16 operat… 2020-03-30
## 8 8 Inaatasan and DOT at iban… IATF resolu… 16 operat… 2020-03-30
## 9 9 pagtukoy ng mga pasilidad… IATF resolu… 16 operat… 2020-03-30
## 10 10 Ang mga natukoy na pasili… IATF resolu… 16 operat… 2020-03-30
## # … with 77 more rowsWhilst it is possible to perform multi-lingual sentiment analysis, there is still no reliable sentiment lexicon (see following section for definition) for Filipino. Leaving out IATF Resolution No. 16, we arrive at the following concatenated IATF resolutions
## # A tibble: 5,774 x 7
## linenumber text source type id section date
## <int> <chr> <chr> <chr> <dbl> <chr> <date>
## 1 1 Republic of the Philippin… IATF resolu… 1 heading 2020-01-28
## 2 2 Department of Health IATF resolu… 1 heading 2020-01-28
## 3 3 Office of the Secretary IATF resolu… 1 heading 2020-01-28
## 4 4 Inter-Agency Task Force f… IATF resolu… 1 heading 2020-01-28
## 5 5 Emerging Infectious Disea… IATF resolu… 1 heading 2020-01-28
## 6 6 28 January 2020 IATF resolu… 1 heading 2020-01-28
## 7 7 Resolution No. 01 IATF resolu… 1 heading 2020-01-28
## 8 8 Series of 2020 IATF resolu… 1 heading 2020-01-28
## 9 9 Recommendations for the M… IATF resolu… 1 heading 2020-01-28
## 10 10 Novel Coronavirus Situati… IATF resolu… 1 <NA> 2020-01-28
## # … with 5,764 more rowswith 7 columns and 5774 rows of text. We then consider whether all the sections of a resolution is going to be useful for sentiment analysis. A typical resolution is composed of 3 sections:
Heading - contains the body proposing the resolution, the subject of the resolution, the resolution number and the date resolution is issued;
Preambulatory clauses - contains the preamble statements of the resolution i.e., the reasons for which the proposing body is addressing the issue and highlights past action done by the body or any other organisation regarding the issue. This is usually composed of a series of phrases that starts with the WHEREAS
Operative clauses - contains phrases/statements that offer solutions to the issues stated in the preamble.These phrases are action-oriented starting with a verb followed by the proposed solution. This section usually starts off with LET IT BE RESOLVED
The IATF Resolutions very much follow the aforementioned structure with the addition of a section stating the approval of the resolution and the signatories approving the resolution, and in later resolutions a section certifying that the resolution has been approved.
For purposes of sentiment analysis, the most meaningful sections to use will be the sections on preambulatory clauses and operative clauses. So, we further subset the concatenated text dataset of IATF Resolutions to only contain those that are preambulatory and operative clauses. You will notice that in the text data of each of the IATF Resolutions, these sections have been identified through the variable named section. We use this variable to filter the sections we need as follows:
allText <- allText %>%
filter(section %in% c("preamble", "operative"))which results in
## # A tibble: 4,048 x 7
## linenumber text source type id section date
## <int> <chr> <chr> <chr> <dbl> <chr> <date>
## 1 11 WHEREAS, Executive Order N… IATF resol… 1 preamb… 2020-01-28
## 2 12 for the Management of Emer… IATF resol… 1 preamb… 2020-01-28
## 3 13 WHEREAS, the Inter-agency … IATF resol… 1 preamb… 2020-01-28
## 4 14 identify, screen, and assi… IATF resol… 1 preamb… 2020-01-28
## 5 15 prevent and/or minimize th… IATF resol… 1 preamb… 2020-01-28
## 6 16 as prevent and/or minimize… IATF resol… 1 preamb… 2020-01-28
## 7 17 WHEREAS, on January 7, 202… IATF resol… 1 preamb… 2020-01-28
## 8 18 the viral pneumonia outbre… IATF resol… 1 preamb… 2020-01-28
## 9 19 (2019-nCoV) that has not b… IATF resol… 1 preamb… 2020-01-28
## 10 20 WHEREAS, as of January 27,… IATF resol… 1 preamb… 2020-01-28
## # … with 4,038 more rowsWe are now left with 4048 rows of text for sentiment analysis.
Finally, we perform some final data cleaning and processing that will be useful when performing sentiment analysis. We convert the word COVID-19 to COVID19 without the dash. Since this word will most likely be a critical word in this analysis, we wanted to ensure that we capture it in its entirety. The next step on tokenisation removes any punctuation used in the text including dashes and will treat COVID as a separate word from 19. We remove the dash prior to tokenisation so that we can keep these two as one word.
allText$text <- str_replace_all(string = allText$text,
pattern = "COVID-19",
replacement = "COVID19")And then, anticipating that we will need some kind of grouping variable later in the analysis, we create a month variable within the concatenated text dataset that indicates the month when a specific resolution was issued. This was done as follows:
allText <- allText %>%
mutate(month = factor(x = months(date),
levels = c("January", "February", "March",
"April", "May", "June")))Our final working text dataset is this:
## # A tibble: 4,048 x 8
## linenumber text source type id section date month
## <int> <chr> <chr> <chr> <dbl> <chr> <date> <fct>
## 1 11 WHEREAS, Executive O… IATF resol… 1 preamb… 2020-01-28 Janu…
## 2 12 for the Management o… IATF resol… 1 preamb… 2020-01-28 Janu…
## 3 13 WHEREAS, the Inter-a… IATF resol… 1 preamb… 2020-01-28 Janu…
## 4 14 identify, screen, an… IATF resol… 1 preamb… 2020-01-28 Janu…
## 5 15 prevent and/or minim… IATF resol… 1 preamb… 2020-01-28 Janu…
## 6 16 as prevent and/or mi… IATF resol… 1 preamb… 2020-01-28 Janu…
## 7 17 WHEREAS, on January … IATF resol… 1 preamb… 2020-01-28 Janu…
## 8 18 the viral pneumonia … IATF resol… 1 preamb… 2020-01-28 Janu…
## 9 19 (2019-nCoV) that has… IATF resol… 1 preamb… 2020-01-28 Janu…
## 10 20 WHEREAS, as of Janua… IATF resol… 1 preamb… 2020-01-28 Janu…
## # … with 4,038 more rowsStep 2: Tokenise data
We are now ready to tokenise the data. Tokenisation of text data simply means structuring the text data into tokens – meaningful units of text such as a word, or groups of words, or a sentence, or a paragraph. For sentiment analysis, the most useful token will be a word mainly because the sentiment lexicons (see following section for definition) we plan to use are based on words.
We use the tidytext package and the function unnest_tokens within it to perform tokenisation using words as follows:
tidy_resolutions <- allText %>%
unnest_tokens(output = word, input = text)This results in the following dataset:
## # A tibble: 40,024 x 8
## linenumber source type id section date month word
## <int> <chr> <chr> <dbl> <chr> <date> <fct> <chr>
## 1 11 IATF resolution 1 preamble 2020-01-28 January whereas
## 2 11 IATF resolution 1 preamble 2020-01-28 January executive
## 3 11 IATF resolution 1 preamble 2020-01-28 January order
## 4 11 IATF resolution 1 preamble 2020-01-28 January no
## 5 11 IATF resolution 1 preamble 2020-01-28 January 168
## 6 11 IATF resolution 1 preamble 2020-01-28 January s
## 7 11 IATF resolution 1 preamble 2020-01-28 January 2014
## 8 11 IATF resolution 1 preamble 2020-01-28 January creates
## 9 11 IATF resolution 1 preamble 2020-01-28 January the
## 10 11 IATF resolution 1 preamble 2020-01-28 January inter
## # … with 40,014 more rowsYou will notice that our new tokenised dataset is structured such that each word in the concatenated IATF Resolutions of preambles and operative clauses is a unit of data i.e. in a row. We now have a dataset with 40024 rows and 8 columns that we can use for the next step.
Step 3: Apply sentiment lexicon
We now apply a sentiment lexicon onto the tokenised dataset from the previous step. Sentiment lexicons are basically a list of common words in a specific language with each word having a value pertaining to the sentiment or emotion associated with a specific word. The value assigned to a word can be binary i.e. negative or positive, or can be categories of sentiments or emotions such as positive, negative, anger, anticipation, disgust, fear, joy, sadness, surprise, and trust, or a numerical value on a scale that runs from negative values indicating progressively negative sentiments to positive values indicating progressively positive sentiments.
The tidytext package comes with three general use lexicons:
AFINN- from Finn Årup Nielsen which is a lexicon that assigns a score to words from -5 to +5 with negative scores indicating negative sentiments and positive scores indicating positive sentiments;bing- from Bing Liu and collaborators which is a lexicon that simply classifies words into either negative or positive categories; and,nrc- from Saif Mohammad and Peter Turney which is a lexicon that groups words into categories of positive, negative, anger, anticipation, disgust, fear, joy, sadness, surprise, or trust
Below we describe how to apply these sentiment lexicons to the tokenised data. The techniques described below in applying sentiment onto a text dataset are not the only ways to approach sentiment analysis but they are the most basic and common approaches used. These approaches treat the text dataset as a “bag of words” such that the sentiment content of the whole dataset is the sum of the sentiment content of each of the words in the dataset.
Labeling words in the dataset as having positive or negative sentiment
We apply the sentiment lexicon from Bing and colleagues to our tokenised data as follows:
resolution_sentiment_bing <- tidy_resolutions %>%
inner_join(get_sentiments("bing"))What we are basically doing here is to match the words in our tokenised data with the words in the sentiment lexicon from Bing and colleagues to get the sentiment value of positive or negative for our tokenised data. This results in the following sentiment-orientated IATF word token dataset:
## # A tibble: 1,303 x 9
## linenumber source type id section date month word sentiment
## <int> <chr> <chr> <dbl> <chr> <date> <fct> <chr> <chr>
## 1 14 IATF resolu… 1 preamble 2020-01-28 Janua… infected negative
## 2 15 IATF resolu… 1 preamble 2020-01-28 Janua… well positive
## 3 18 IATF resolu… 1 preamble 2020-01-28 Janua… outbreak negative
## 4 21 IATF resolu… 1 preamble 2020-01-28 Janua… risk negative
## 5 21 IATF resolu… 1 preamble 2020-01-28 Janua… infecti… negative
## 6 25 IATF resolu… 1 operati… 2020-01-28 Janua… recomme… positive
## 7 26 IATF resolu… 1 operati… 2020-01-28 Janua… support positive
## 8 26 IATF resolu… 1 operati… 2020-01-28 Janua… accurate positive
## 9 27 IATF resolu… 1 operati… 2020-01-28 Janua… timely positive
## 10 27 IATF resolu… 1 operati… 2020-01-28 Janua… support positive
## # … with 1,293 more rowsLabeling words in the dataset as having a specific type of sentiment or emotion
Using the nrc lexicon, we use the same approach as the previous:
resolution_sentiment_nrc <- tidy_resolutions %>%
inner_join(get_sentiments("nrc"))which results in a tokenised dataset of words with associated sentiments or emotions alongside them as shown below:
## # A tibble: 8,028 x 9
## linenumber source type id section date month word sentiment
## <int> <chr> <chr> <dbl> <chr> <date> <fct> <chr> <chr>
## 1 11 IATF resolut… 1 preamble 2020-01-28 Janua… inter negative
## 2 11 IATF resolut… 1 preamble 2020-01-28 Janua… inter sadness
## 3 11 IATF resolut… 1 preamble 2020-01-28 Janua… task positive
## 4 11 IATF resolut… 1 preamble 2020-01-28 Janua… force anger
## 5 11 IATF resolut… 1 preamble 2020-01-28 Janua… force fear
## 6 11 IATF resolut… 1 preamble 2020-01-28 Janua… force negative
## 7 12 IATF resolut… 1 preamble 2020-01-28 Janua… manage… positive
## 8 12 IATF resolut… 1 preamble 2020-01-28 Janua… manage… trust
## 9 12 IATF resolut… 1 preamble 2020-01-28 Janua… infect… disgust
## 10 12 IATF resolut… 1 preamble 2020-01-28 Janua… infect… fear
## # … with 8,018 more rowsScoring words by their level of positive or negative sentiment
Using the AFINN lexicon, we use the same approach as the previous:
resolution_sentiment_afinn <- tidy_resolutions %>%
inner_join(get_sentiments("afinn"))which results in a tokenised dataset of words with associated sentiment scores ranging from -5 (highly negative) to +5 (highly positive).
Step 4 and 5: Summarise sentiment-orientated word token dataset and visualise summaries
We can now make various summaries with the sentiment-orientated datasets from the previous step and then visualise the output. Summaries and visualisation go hand-in-hand and these steps will be influenced by what questions you want answered by the sentiment analysis. Here we ask some questions with regard to sentiments in the IATF resolutions and demonstrate how we can summarise and visualise the data to answer the questions.
Question 1: How does the sentiment change throughout each resolution and over time?
To answer this question, we count how many positive and negative words there are in a specified block of text in the resolutions (referred to as the index). To decide what a meaningful block of text or index would be for a resolution, we need to remember that resolutions tend to be written in a very structured and concise way and that meaning can already be derived within short chunks of text. So, for this, we use an index of 5 lines at most.
We perform this using the tokenised dataset resolution_sentiment_bing which has a binary sentiment value of positive or negative:
resolution_sentiment_bing %>%
count(id, date, index = linenumber %/% 5, sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative)## # A tibble: 631 x 6
## id date index negative positive sentiment
## <dbl> <date> <dbl> <dbl> <dbl> <dbl>
## 1 1 2020-01-28 2 1 0 -1
## 2 1 2020-01-28 3 1 1 0
## 3 1 2020-01-28 4 2 0 -2
## 4 1 2020-01-28 5 0 6 6
## 5 1 2020-01-28 6 3 0 -3
## 6 2 2020-01-31 2 0 2 2
## 7 2 2020-01-31 3 1 2 1
## 8 2 2020-01-31 4 1 0 -1
## 9 2 2020-01-31 5 2 0 -2
## 10 2 2020-01-31 6 0 1 1
## # … with 621 more rowsWe then visualise this output using a bar chart for each resolution as shown below:
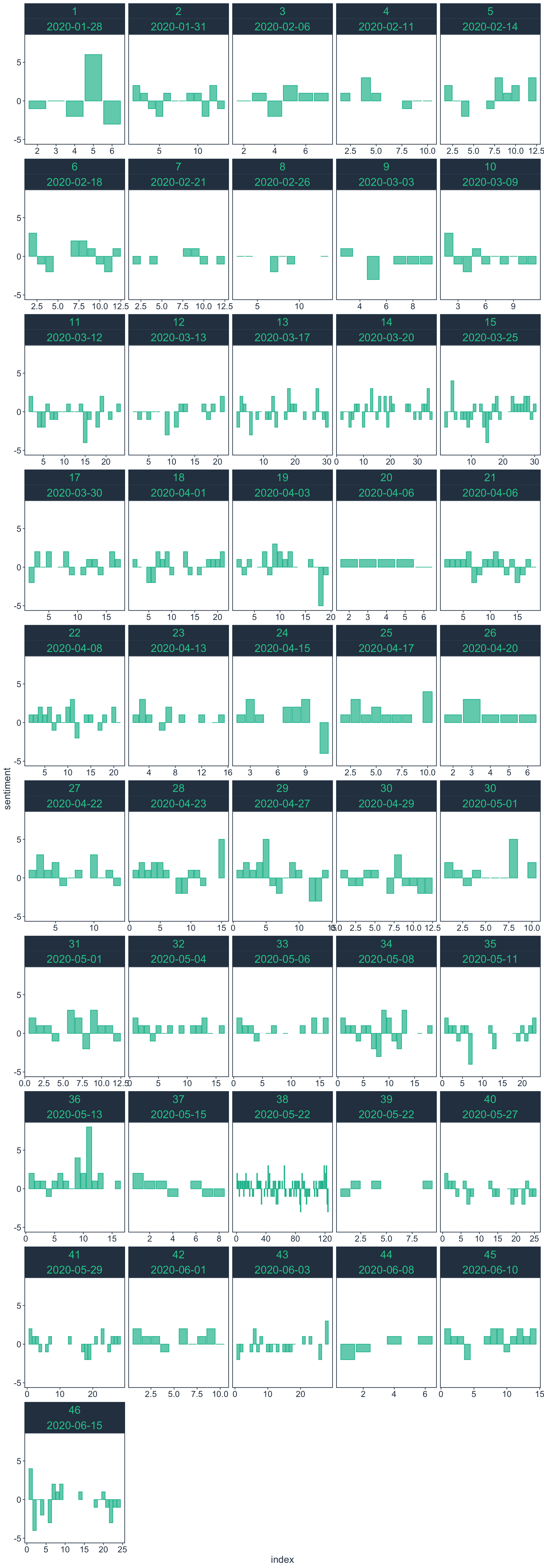
Figure 2: Sentiment change throughout each resolution
In interpreting our output to answer the question, we can treat each of the individual bar charts as describing what the pattern of sentiment is within a single resolution (as each resolution have been issued on a specific date) and we can think of the whole collection of bar charts by date as a time-series given that each resolution was issued chronologically from January up to current date. So, in the bar chart, moving from left to right starting from the first row of bar charts to the last, we are seeing the progression of sentiments in the IATF over time since January to current date.
General observations are:
No discernible and consistent intra-resolution pattern of sentiment. This is interesting given that we took both the preambulatory and operative clauses section only which by definition can each have a different tone and sentiment. A naive assumption can be that preambulatory clauses section can be more negative in that it states the issues that are being resolved by the resolution whilst the operative clauses section is meant to be action oriented hence more positive. But given that the whole topic is about a pandemic and its control, actions taken to address the issue can be negative such as quarantine, lockdown, limitation of movement, etc.
The resolutions start out as relatively shorter texts from January 2020 up to 9 March 2020 (first 2 rows of bar charts). By the 12th of March 2020, the amount of text increases to an almost consistent amount up to current date except during the period of the second week of April 2020;
Resolutions issued from January 2020 to 3 April 2020 tended to be more negative whilst resolutions after this date tended to be more positive.
Question 2: How does the sentiment change by month?
In the previous question and in the outputs we produced to provide answers to that question, no clear patterns showed based on a resolution-by-resolution summary and visualisation. In this question, the level of aggregation is by month which will mean at least 2-3 resolutions grouped together. We perform this summary as follows:
resolution_sentiment_bing %>%
count(month, index = linenumber %/% 5, sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative)## # A tibble: 207 x 5
## month index negative positive sentiment
## <fct> <dbl> <dbl> <dbl> <dbl>
## 1 January 2 1 2 1
## 2 January 3 2 3 1
## 3 January 4 3 0 -3
## 4 January 5 2 6 4
## 5 January 6 3 1 -2
## 6 January 7 1 1 0
## 7 January 8 1 1 0
## 8 January 9 0 1 1
## 9 January 10 0 1 1
## 10 January 11 2 0 -2
## # … with 197 more rowsWe then visualise this in a similar manner as above but with months as the grouping variable. We get the following output:
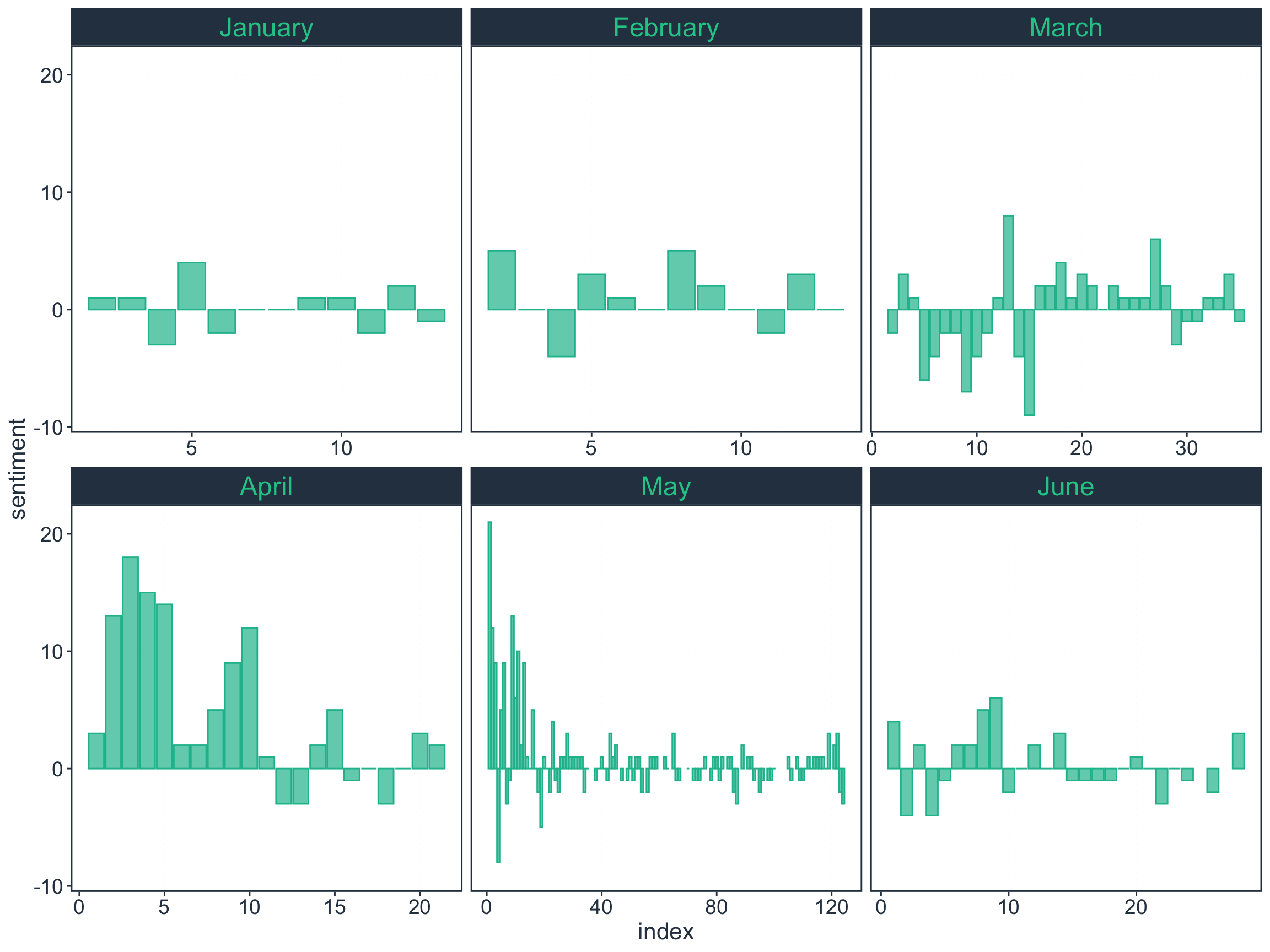
Figure 3: Sentiment change by month
With this summary and visualisation, we confirm our earlier observation of resolutions being shorter texts in January and February 2020. Also, there is a more discernible intra-month pattern of sentiment particularly starting in March 2020 onwards. March 2020 starts off in a more negative which then picks up as more positive later on. April 2020 on the other hand is predominantly positive. May 2020 has the most amount of text (most number of resolutions). Earlier resolutions in May 2020 were highly positive which eventually tapers off to a mix of sentiments moving forward. By June 2020, the sentiments seem to be returning to something similar to the January to February 2020 pattern of relatively more positive sentiments.
Question 3: What is the sentiment change across all resolutions?
We’ve summarised the sentiments by resolution by month. Now we’d like to see what the overall progression of sentiment is through the full body of text of preambles and operative clauses. We summarise and visualise the data as follows:
resolution_sentiment_bing <- tidy_resolutions %>%
inner_join(get_sentiments("bing")) %>%
count(index = linenumber %/% 5, sentiment) %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative)
ggplot(resolution_sentiment_bing, aes(index, sentiment)) +
geom_col(colour = "#18BC9C",
fill = "#18BC9C",
alpha = 0.7,
show.legend = FALSE) +
theme_como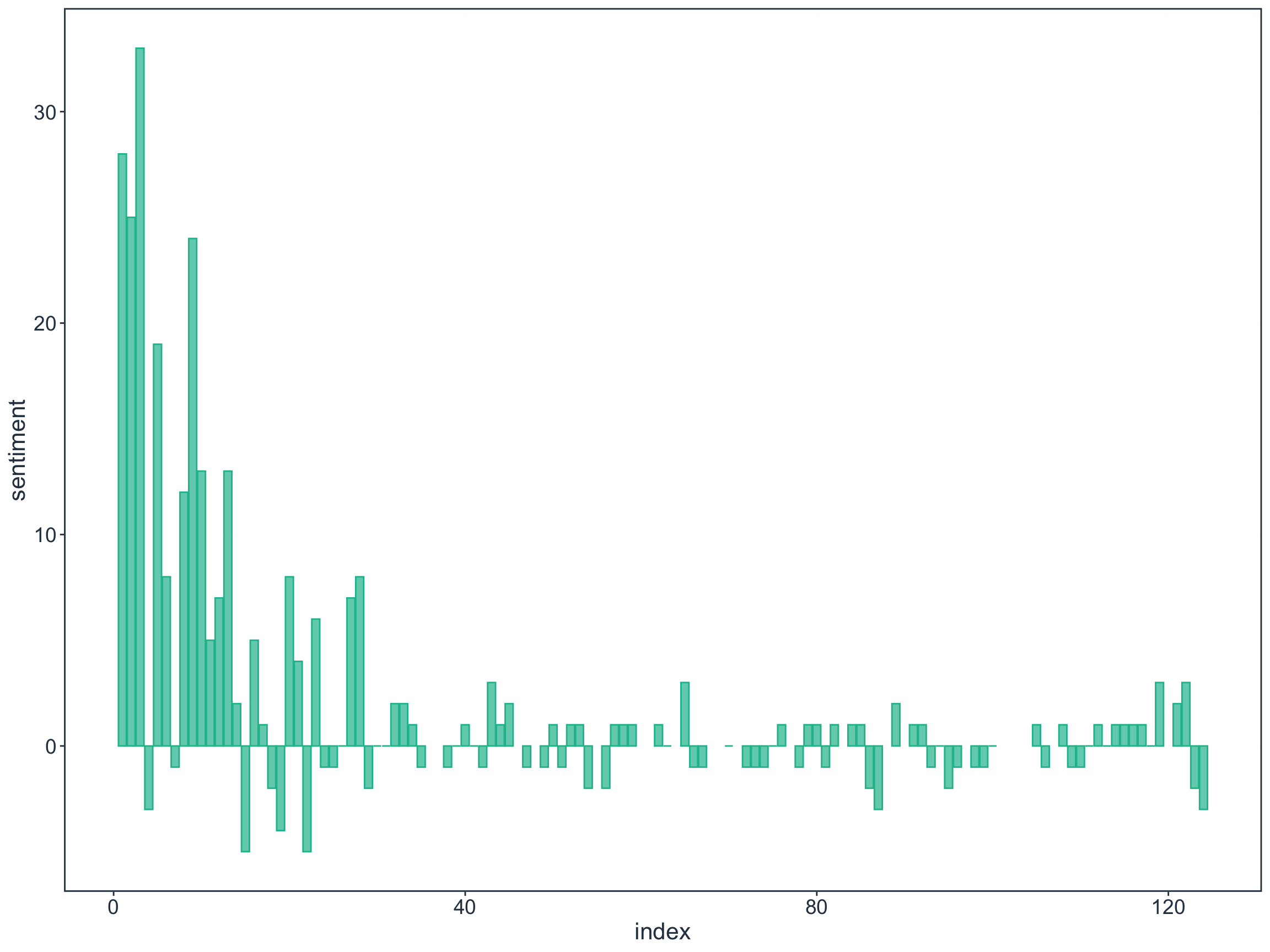
Figure 4: Sentiment change across all resolutions
Strongly positive sentiment early on in the text (earlier resolutions in the January to February 2020 period) which then tapers off in March 2020. From then onwards, its been a relatively even mix of positive and negative sentiments.
Question 4: Which words contribute the most to positive and negative sentiments?
Now what we know the trend of sentiments in the resolutions across time and overall, we’d like to know which words contribute the most to positive and negative sentiments. We summarise and visualise the data to answer this question as follows:
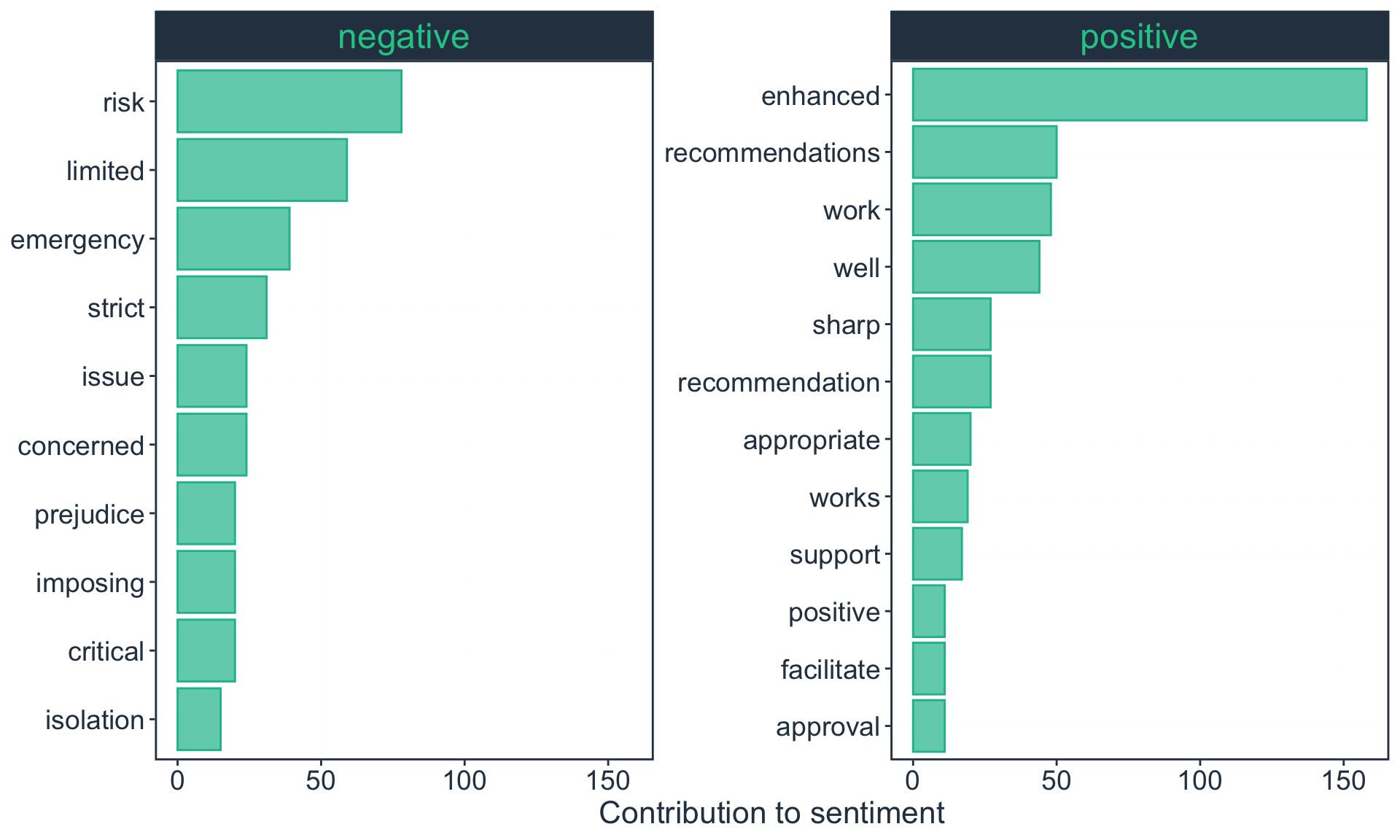
Figure 5: Top ten words that contribute to positive and negative sentiment
Another way of visualising the same information:
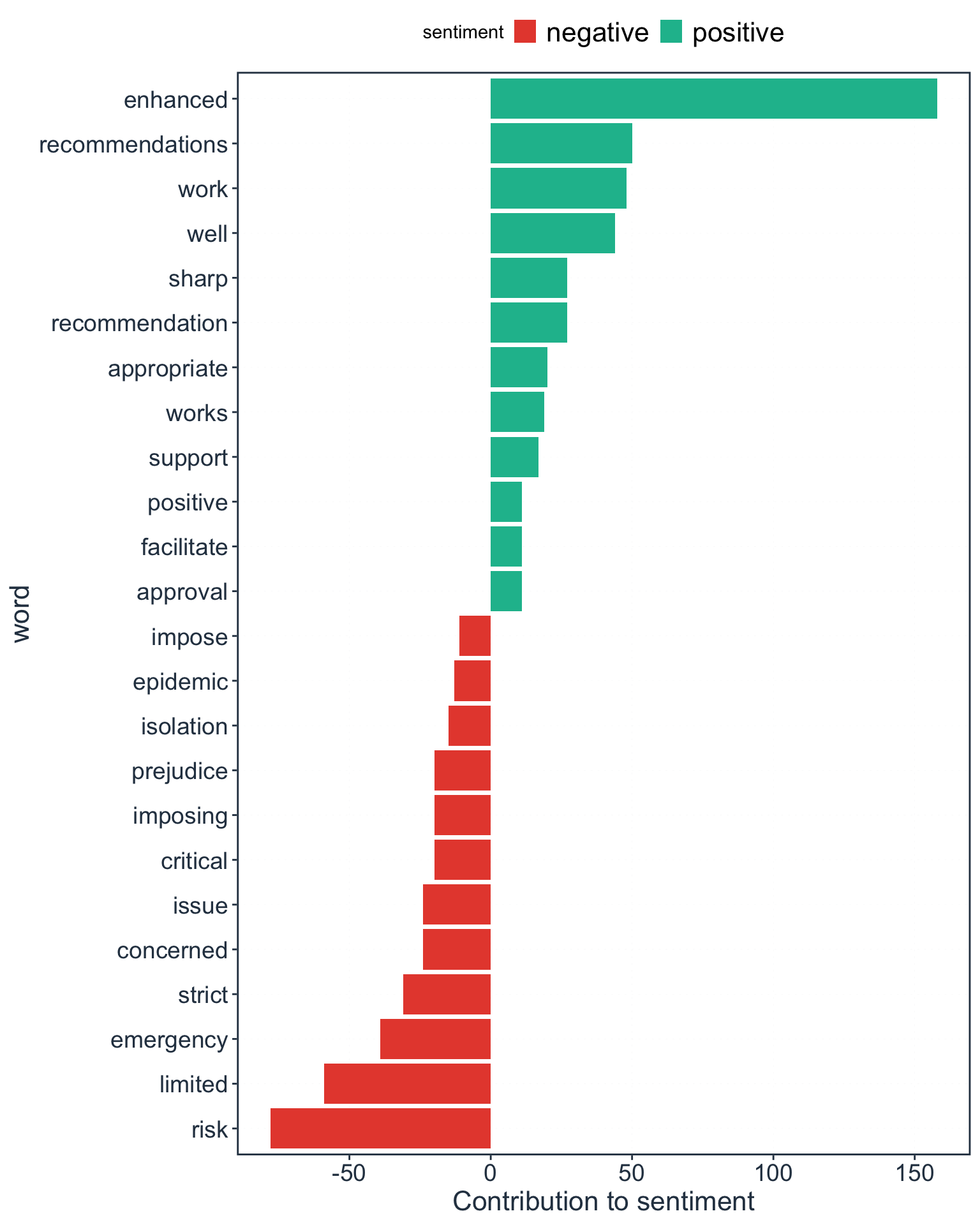
Figure 6: Top ten words that contribute to positive and negative sentiment
These top ten words contributing to positive and negative sentiments are consistent with what we would expect from a body of text that talk about a health emergency i.e., pandemic and consistent with the nature of the text itself i.e., resolutions which talk about the issues related to the situation/context and actions to be taken in response.
Question 5: What is the overall sentiment value of each resolution?
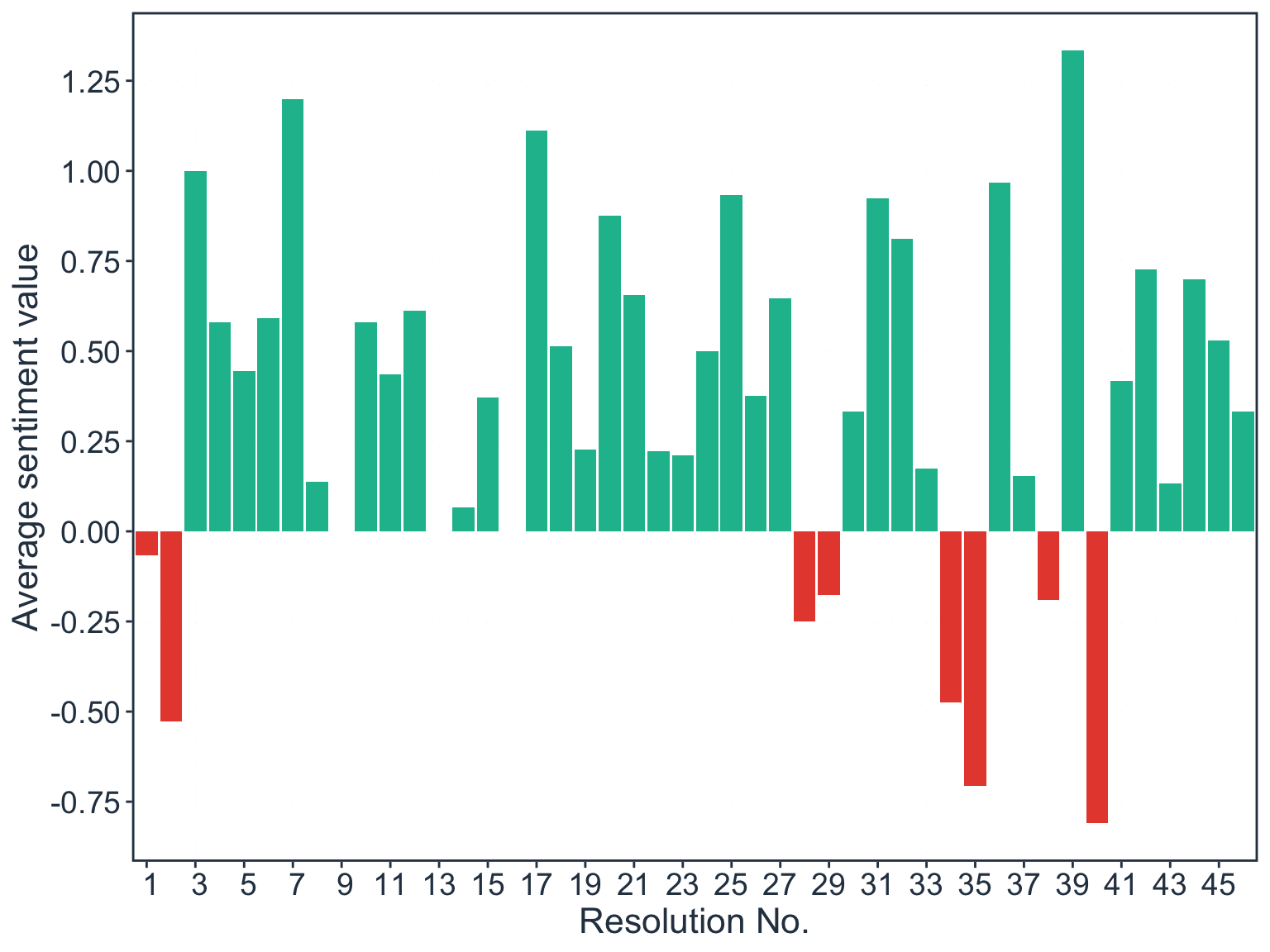
Figure 7: Average sentiment value per resolution
Eight out of the 46 resolutions analysed had a negative average sentiment value. These resolutions were during the early stages of the response (January 2020) and in the height of the response (late April 2020 to May 2020).
Question 6: What is the average sentiment value contribution of specific words
To answer this question we use the AFINN sentiment lexicon which assigns a numerical score for positive and negative sentiments ranging from -5 to +5 respectively. Once we have assigned sentiment scores to the words, we do a counting of the words and then calculate a sentiment value per word by multiplying the sentiment score for the word with the proportion of the frequency of the word with the total frequency of all the words.
\[ \text{Sentiment value} ~ = ~ \text{Sentiment score} ~ \times ~ \frac{\text{Word frequency}}{\sum{\text{World frequency}}}\]
To get to this answer, we summarise and visualise the data as follows:
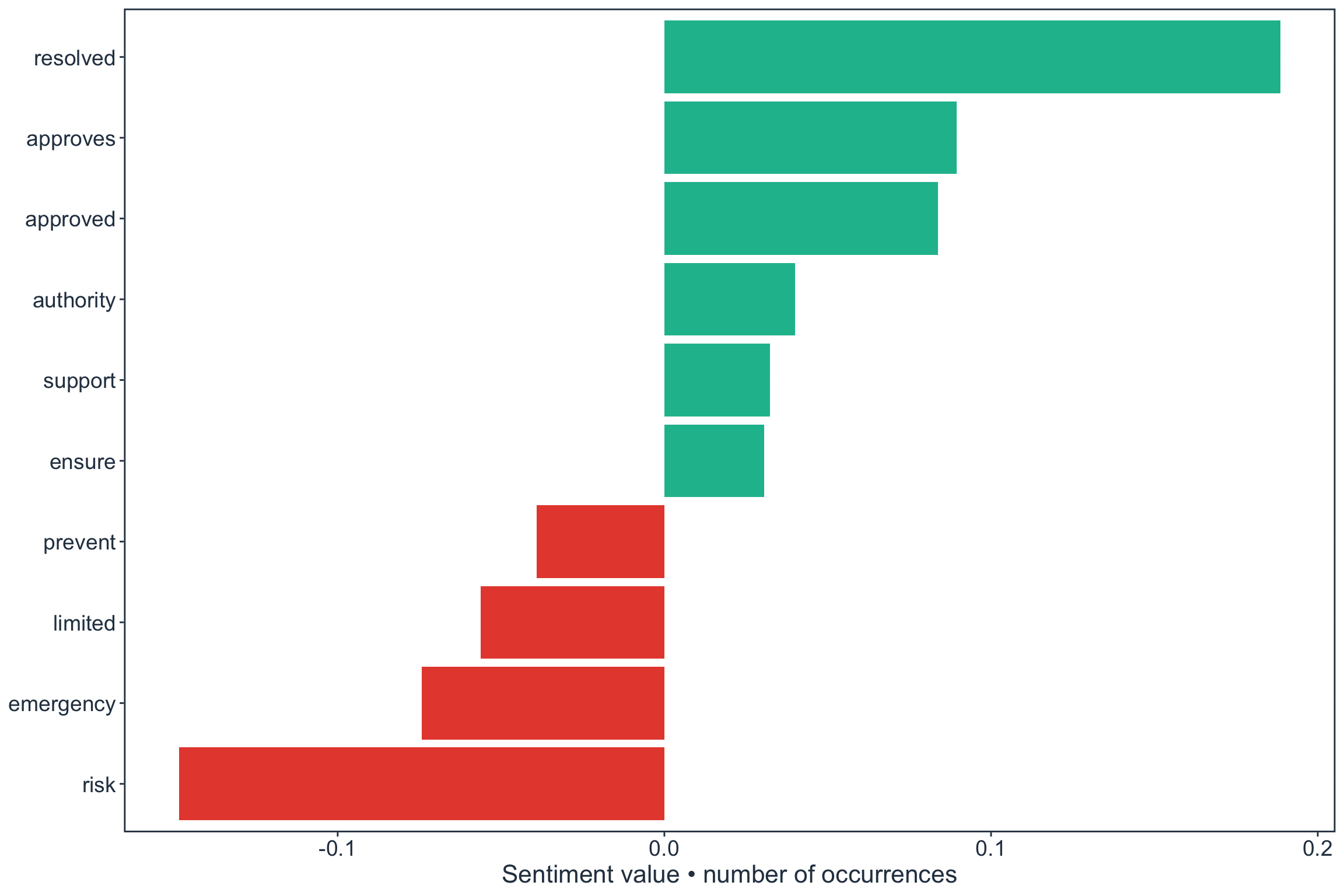
Figure 8: Sentiment value of words across all resolutions
Of the top ten most frequent words from all the resolutions, 6 have positive sentiment value and 4 with negative sentiment value. All top ten words are indicative of the nature of the text dataset that we are analysing. The top words for positive sentiment have roughly similar sentiment value as the top words for negative sentiment.
We disaggregate the results for resolutions per month as below:
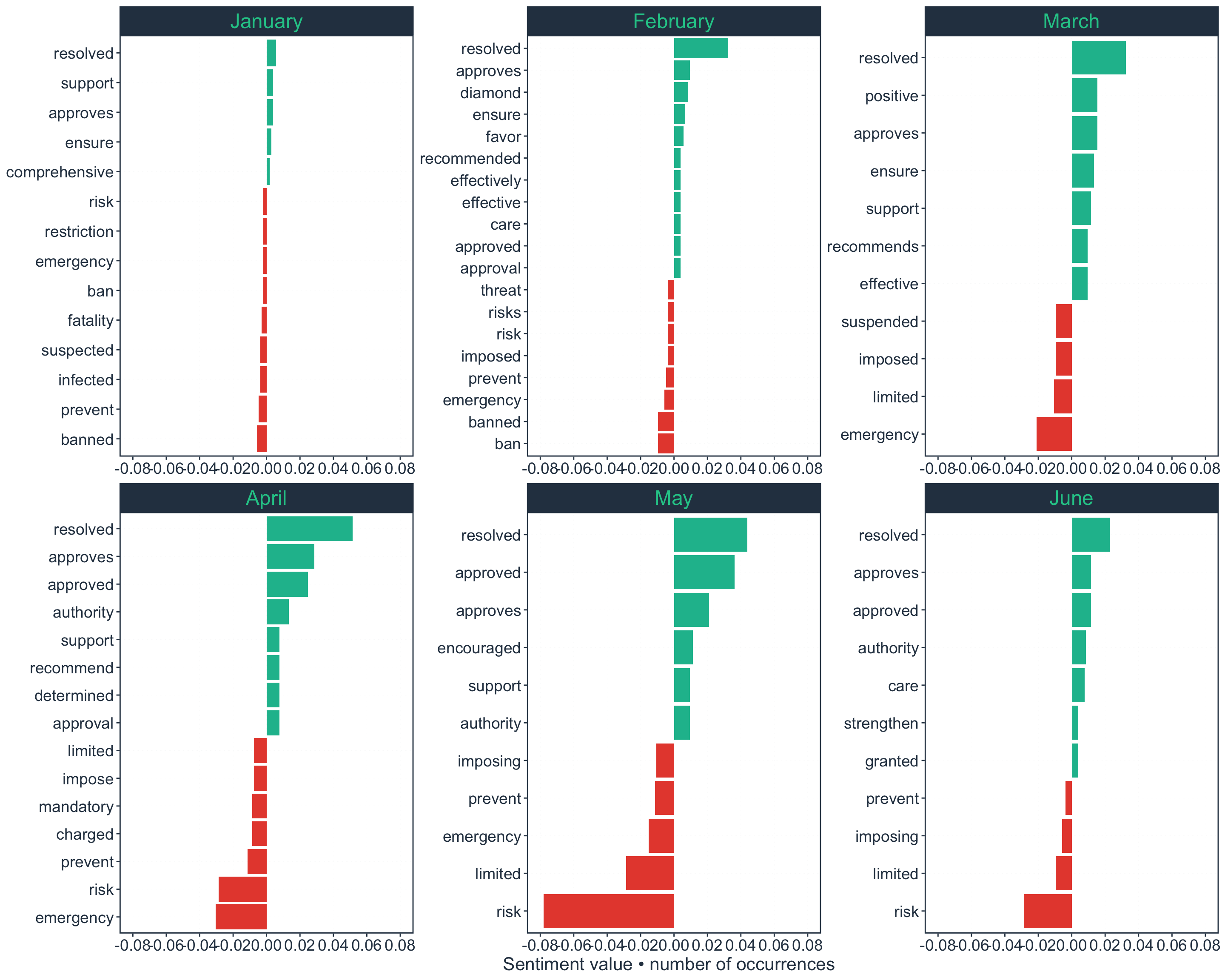
Figure 9: Sentiment value of words across all resolutions by month
Resolutions for April and May mirror the words and the sentiment value for the entire dataset.
Mäntylä MV, Graziotin D, Kuutila M. The evolution of sentiment analysis—A review of research topics, venues, and top cited papers. Computer Science Review. 2018;27: 16–32. doi:10.1016/j.cosrev.2017.10.002↩︎
Liu B. Handbook Chapter: Sentiment Analysis and Subjectivity. Handbook of Natural Language Processing, Handbook of Natural Language Processing, Marcel Dekker, Inc. New York, NY, USA (2009)↩︎